v8历史
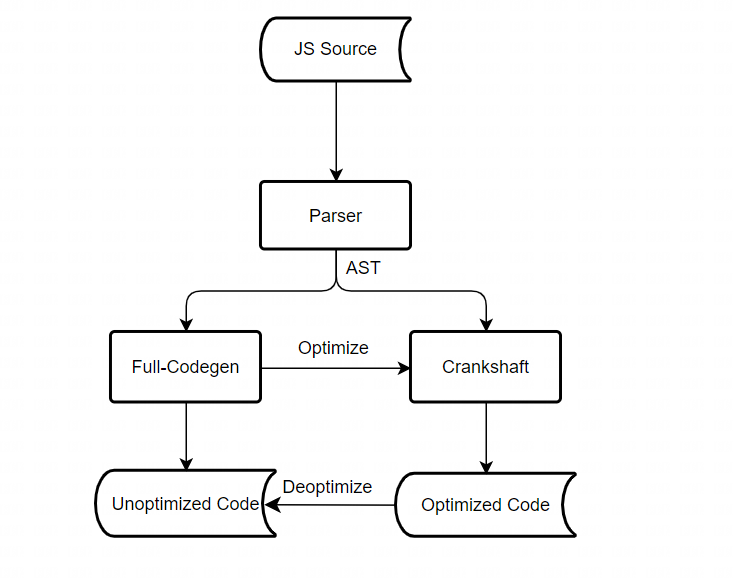
早期的v8执行管道只有两个编译器:基线编译器Full-Codegen、优化编译器Crankshaft,Full-Codegen用于通过AST直接生成未经过优化的机器码,Crankshaft用于对生成的机器码进行优化,当发生解优化时再回退到未经优化的机器码继续执行,其中基线编译器更侧重于编译速度,优化编译器更侧重执行速度:
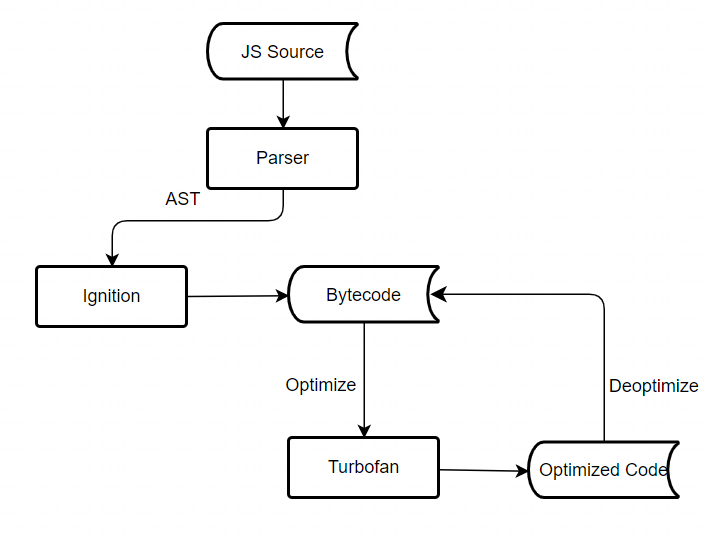
之后由于结构层混乱并且内存占用过大等问题又衍生出了由解析器Parser、基线编译器Ignition、优化编译器Turbofan组成的执行管道,先由解析器分析得到AST语法树,随后Ignition将会通过AST语法树得到字节码,最后Turbofan再将字节码转换成中间层(IR)进行相应的优化输出成最终的机器码,当遇到解优化的情况时再回退到字节码执行:
上面的执行管道还有些不足,字节码需要通过Ignition进行解释执行效率远不如直接执行Full-Codegen生成的机器码,所以后来又出现了Ignition、Turbofan、Full-Codegen、Crankshaft组合的执行管道结构,此结构比较复杂且我的了解有限不详述。
随后弥补之前结构中的一些不足,又衍生出了新的结构也是目前v8主要使用的结构:
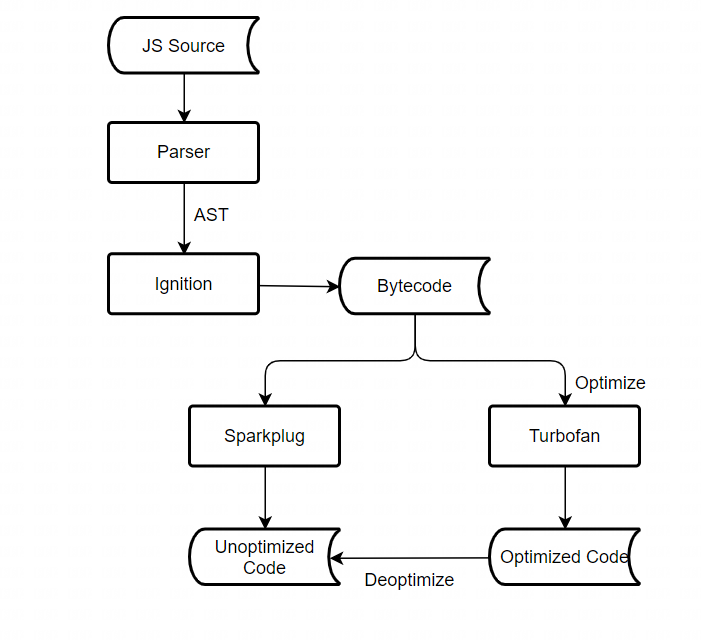
Sparkplug与之前的Full-Codegen有相似之处,它们都会生成未经优化的机器码,但区别在于Full-Codegen通过AST语法树来生成,而Sparkplug通过字节码来生成,通过字节码来生成机器码优势在于变量分析、语法糖解析等工作全都由字节码生成器来完成,而Sparkplug只需要用字节码来生成与之完全对应的机器码即可。由于是直接通过字节码生成不进行优化,所以也就意味着Sparkplug的编译速度非常快。Turbofan的优化很耗编译时间与计算能力,对于一些调用频率相对较小的代码使用Turbofan是不划算的,所以对于这种情况就会直接使用Sparkplug来生成未经优化的机器码,而机器码的执行效率又高于Ignition生成的字节码,而根据我的理解当Turbofan发生解优化时也是回退到未经优化的机器码去执行的而不是直接回退到字节码。
阅读一些v8的有关文档会发现其中提到了四层结构,现在看来这四层结构应该是Ignition、Sparkplug、Maglev、Turbofan而在早期Maglev未出现之前谷歌使用了一个基于Turbofan的轻量级中间编译器TurboProp,它属于是Turbofan的子集,简化了Turbofan中的一些重大优化以此来生成一些优化程度介于Turbofan与Sparkplug之间的机器码,但TurboProp依然存在一些冗余的优化过程,于是为了能更好的权衡编译速度与执行速度谷歌决定开发一个新的轻量级SSA优化编译器也就是Maglev。
此处要注意的是依据我的理解,这些编译器之间生成的代码并没有传递关系,它们都是独立运作的,比如只要函数体足够大并且当循环次数(也可能是代码的执行持续时间)大约在0x100次左右时就会触发Sparkplug然后去执行其生成的未优化机器码,当循环次数大约在0x1000次左右时就会触发Turbofan然后去执行其生成的优化机器码,Maglev目前可能还在试验阶段需要添加启动参数才能触发,但其最终应该也会像前两者一样。
源码分析
Parser(源码解析器)
当在shell(d8)下执行js代码时会从v8::Shell::Main函数开始,然后通过以下路径调用到脚本编译主线程函数CompileScriptOnMainThread:
#5 v8::internal::(anonymous namespace)::CompileScriptOnMainThread (flags=..., source=source@entry=..., script_details=..., natives=natives@entry=v8::internal::NOT_NATIVES_CODE, extension=extension@entry=0x0, isolate=0x5555555d23f0, maybe_script=..., is_compiled_scope=0x7fffffffd820) at ../../src/codegen/compiler.cc:3293
#6 0x00007ffff6507c27 in v8::internal::(anonymous namespace)::GetSharedFunctionInfoForScriptImpl (isolate=0x5555555d23f0, source=..., script_details=..., extension=extension@entry=0x0, cached_data=cached_data@entry=0x0, deserialize_task=deserialize_task@entry=0x0, compile_options=v8::ScriptCompiler::kNoCompileOptions, no_cache_reason=v8::ScriptCompiler::kNoCacheNoReason, natives=v8::internal::NOT_NATIVES_CODE) at ../../src/codegen/compiler.cc:3555
#7 0x00007ffff6507643 in v8::internal::Compiler::GetSharedFunctionInfoForScript (isolate=0x7fffffffce68, source=..., script_details=..., compile_options=4142543216, no_cache_reason=4111349840, natives=(unknown: 0x4cd17400)) at ../../src/codegen/compiler.cc:3585
#8 0x00007ffff62747b4 in v8::ScriptCompiler::CompileUnboundInternal (v8_isolate=v8_isolate@entry=0x5555555d23f0, source=source@entry=0x7fffffffdb90, options=options@entry=v8::ScriptCompiler::kNoCompileOptions, no_cache_reason=no_cache_reason@entry=v8::ScriptCompiler::kNoCacheNoReason) at ../../src/api/api.cc:2668
#9 0x00007ffff6274dc0 in v8::ScriptCompiler::Compile (context=..., source=0x7fffffffdb90, options=v8::ScriptCompiler::kNoCompileOptions, no_cache_reason=v8::ScriptCompiler::kNoCacheNoReason) at ../../src/api/api.cc:2697
#10 0x0000555555587051 in v8::(anonymous namespace)::Compile<v8::Script> (context=..., source=0x7fffffffdb90, options=<optimized out>) at ../../src/d8/d8.cc:615
#11 v8::Shell::CompileString<v8::Script> (isolate=isolate@entry=0x5555555d23f0, context=context@entry=..., source=source@entry=..., origin=...) at ../../src/d8/d8.cc:650
#12 0x00005555555867fa in v8::Shell::ExecuteString (isolate=isolate@entry=0x5555555d23f0, source=source@entry=..., name=name@entry=..., print_result=v8::Shell::kNoPrintResult, report_exceptions=<optimized out>, process_message_queue=v8::Shell::kProcessMessageQueue) at ../../src/d8/d8.cc:855
#13 0x000055555559d979 in v8::SourceGroup::Execute (this=0x5555555c72a8, isolate=isolate@entry=0x5555555d23f0) at ../../src/d8/d8.cc:4290
#14 0x00005555555a0b00 in v8::Shell::RunMain (isolate=isolate@entry=0x5555555d23f0, last_run=true) at ../../src/d8/d8.cc:5004
#15 0x00005555555a2d8f in v8::Shell::Main (argc=<optimized out>, argv=<optimized out>) at ../../src/d8/d8.cc:5813
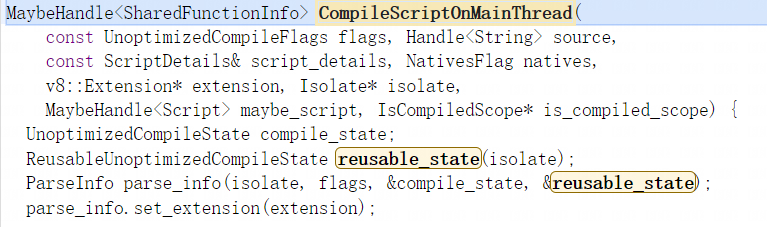
CompileScriptOnMainThread函数会先创建两个编译状态对象,这两个对象都是ParseInfo对象中的字段,这两个对象并不完全一样ReusableUnoptimizedCompileState具有可变属性可以在多个编译中重用,而UnoptimizedCompileState对象正好相反,随后用两个编译状态对象与编译标志以及Isolate对象来创建ParseInfo对象,ParseInfo对象用于保存之后的源码解析结果,然后再为ParseInfo对象设置扩展:
之后通过源码创建Script句柄,调用CompileToplevel函数,CompileToplevel函数只会负责编译顶层的主函数对于其他自定义的函数编译由其他对应的编译函数进入,函数实现代码有些许不同但大致的编译过程与算法逻辑基本都是一致的:

CompileToplevel函数会调用parsing::ParseProgram函数来分析源码并创建初始化AST树,与CompileToplevel类似parsing::ParseProgram函数也只负责分析顶层的主函数其他自定义函数由parsing::ParseFunction函数负责分析,最终的结果保存在ParseInfo对象parse_info中:
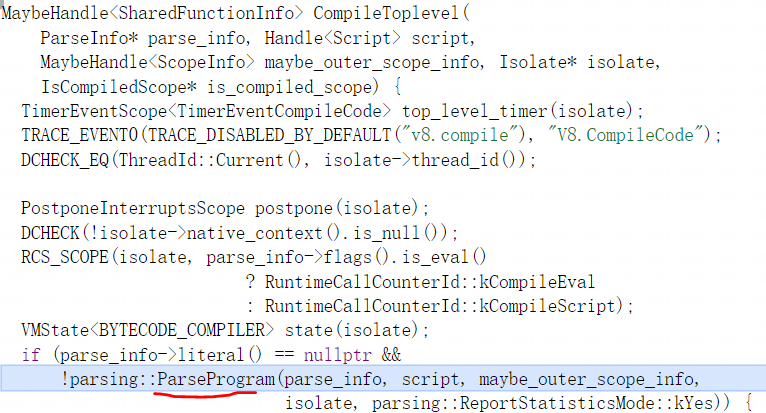
parsing::ParseProgram函数再去Parser::ParseProgram函数,Parser::ParseProgram函数会先创建计时器并初始化分析器状态:

之后先初始化扫描器,再调用DoParseProgram函数开始执行分析:

DoParseProgram函数主要用于获取一些信息并用这些信息创建并初始化FunctionLiteral对象,此对象类的基类是AST节点类AstNode,当在之后分析AST输出函数时就会发现AST树中的各种信息都保存在该对象中:
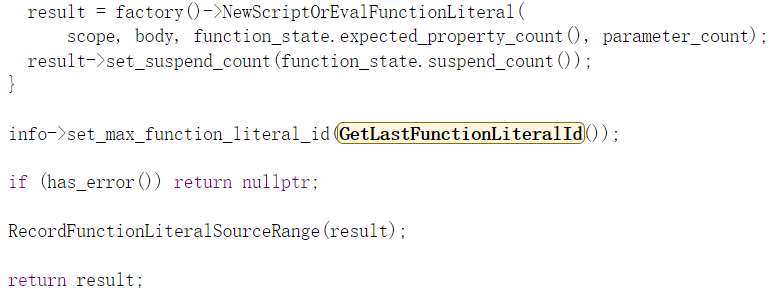


MaybeProcessSourceRanges函数针对于存在源范围映射的情况:

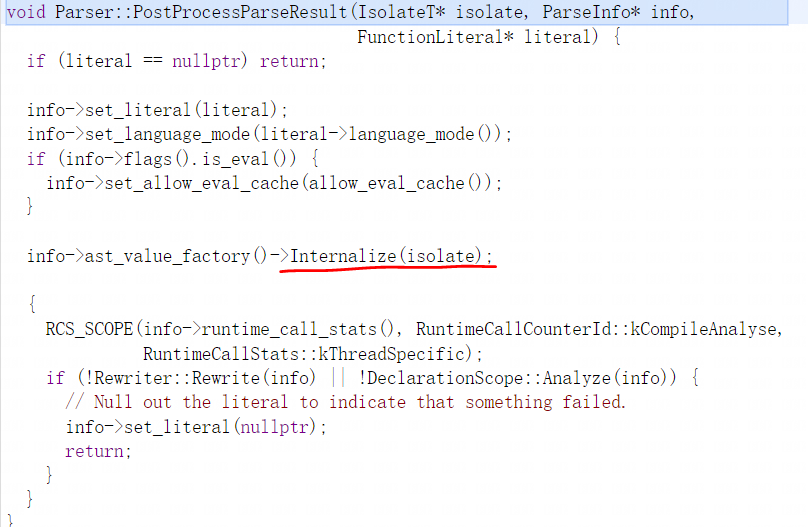
PostProcessParseResult函数用于提交分析结果,其主要功能就是初始化Ast树将其字符串全部内部化:
我认为解析器起主要作用的函数就三个:
- DoParseProgram函数主要负责创建FunctionLiteral对象此对象保存ast树中的各项信息。
- MaybeProcessSourceRanges函数针对于返回的FunctionLiteral对象存在源范围映射的情况
- PostProcessParseResult函数用于提交分析结果FunctionLiteral对象,其主要功能就是将分析结果FunctionLiteral对象保存到ParseInfo对象的字段中并其相关字符串内部化
Ignition(字节码生成器)
解析器ParseProgram函数执行完后会回到CompileToplevel函数,CompileToplevel会将在之前ParseProgram函数中得到的ParseInfo对象传入IterativelyExecuteAndFinalizeUnoptimizedCompilationJobs函数来获取字节码:
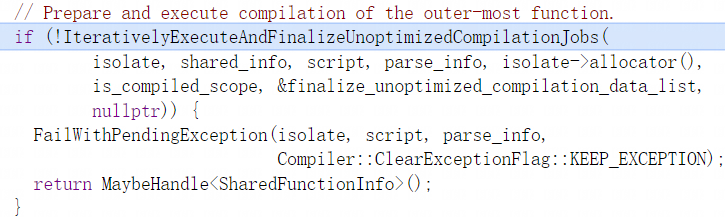
之后IterativelyExecuteAndFinalizeUnoptimizedCompilationJobs函数会通过以下调用路径去调用ExecuteJobImpl函数:
#0 v8::internal::interpreter::InterpreterCompilationJob::ExecuteJobImpl (this=0x5555556330d0) at ../../src/interpreter/interpreter.cc:194
#1 0x00007ffff64f4f1a in v8::internal::UnoptimizedCompilationJob::ExecuteJob (this=0x5555556330d0) at ../../src/codegen/compiler.cc:423
#2 0x00007ffff6515a93 in v8::internal::(anonymous namespace)::ExecuteSingleUnoptimizedCompilationJob (parse_info=parse_info@entry=0x7fffffffd5d0, literal=literal@entry=0x555555652638, script=script@entry=..., allocator=allocator@entry=0x5555555e2df0, eager_inner_literals=eager_inner_literals@entry=0x7fffffffd370, local_isolate=<optimized out>) at ../../src/codegen/compiler.cc:800
#3 0x00007ffff65000b8 in v8::internal::(anonymous namespace)::IterativelyExecuteAndFinalizeUnoptimizedCompilationJobs<v8::internal::Isolate> (isolate=0x5555555d28f0, outer_shared_info=outer_shared_info@entry=..., script=script@entry=..., parse_info=parse_info@entry=0x7fffffffd5d0, allocator=0x5555555e2df0, is_compiled_scope=0x7fffffffd820, finalize_unoptimized_compilation_data_list=0x7fffffffd500, jobs_to_retry_finalization_on_main_thread=0x0) at ../../src/codegen/compiler.cc:842
ExecuteJobImpl函数会先调用MaybePrintAst尝试去打印Ast信息:
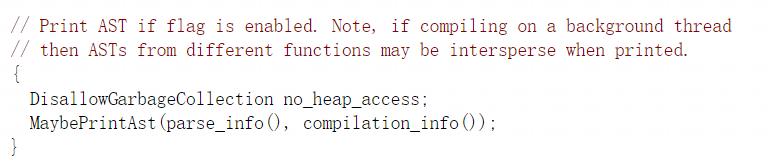
查看MaybePrintAst函数会发现,当启动参数–print-ast为true并且是debug版本时会通过compilation_info->literal_去打印ast的详细信息:
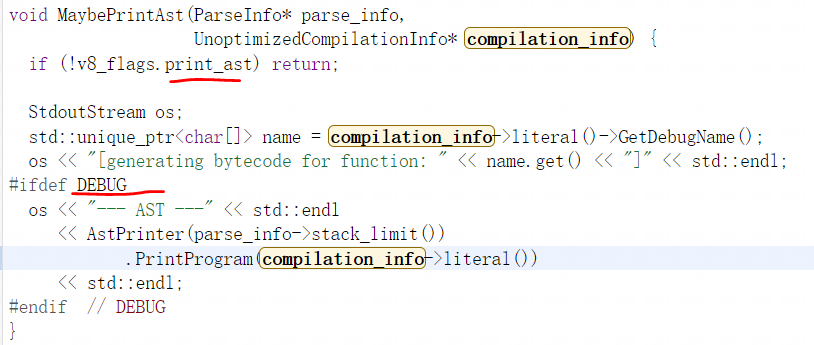
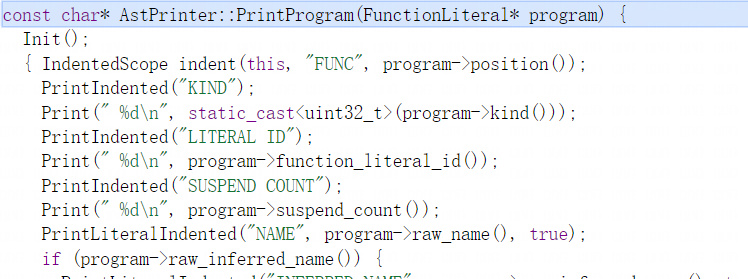
查看compilation_info->literal_会发现他与之前在DoParseProgram函数中得到的FunctionLiteral对象完全是同一个:

通过在启动参数中添加–print-ast查看ast树信息:
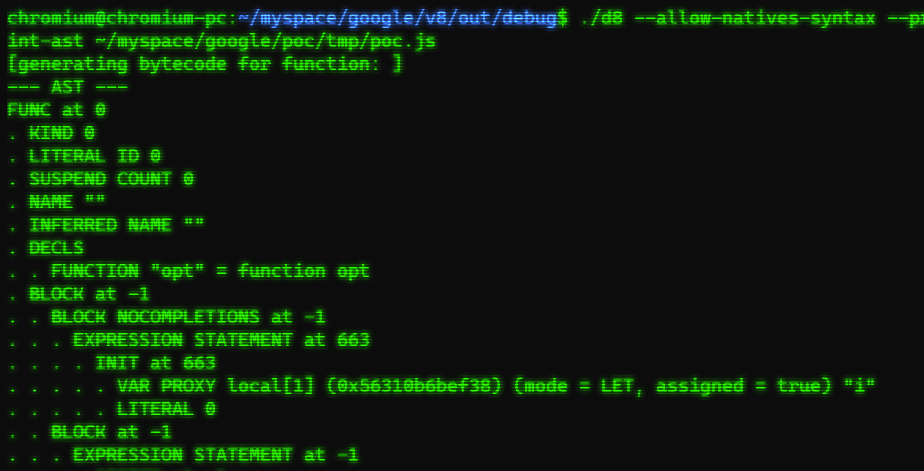
当MaybePrintAst函数执行完毕后,ExecuteJobImpl会去调用BytecodeGenerator::GenerateBytecode函数

BytecodeGenerator::GenerateBytecode函数先初始化AST访问器与传入的上下文,此处的closure_scope就是之前在分析器中获取到的分析结果FunctionLiteral对象的成员变量scope_,然后创建控制流作用域对象,最后创建寄存器作用域对象并分配寄存器,此处的寄存器是字节码中使用的寄存器与机器码/汇编代码中的寄存器不同:
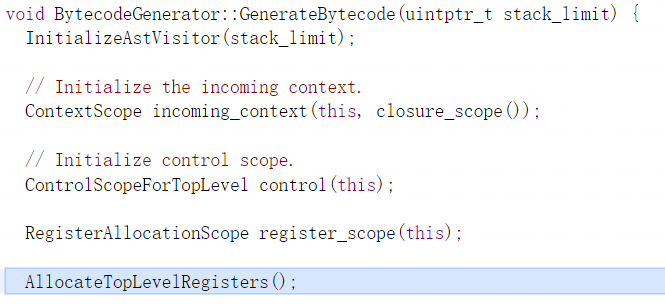

之后会为builder设置并提交起始位置,builder主要负责字节码数组的操作:

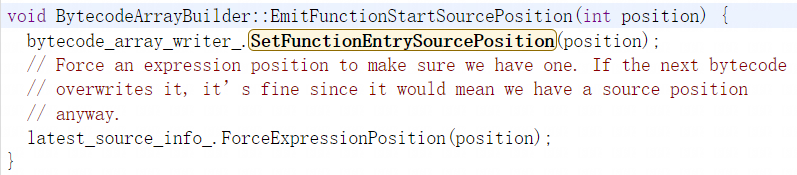
然后通过FunctionLiteral对象判断当前正在处理的函数是否可以挂起,如果可以的话就先去构造生成器序言:

否则就去生成字节码主体,先判断是否需要初始化上下文,如果需要就先进行上下文的创建与初始化再调用GenerateBytecodeBody函数去生成字节码主体,如果不需要就直接开始生成字节码主体:

GenerateBytecodeBody函数会通过访问生成器中的各成员变量来创建相应的字节码,将生成的字节码保存在生成器成员变量builder_->bytecode_array_writer_->bytecodes中:

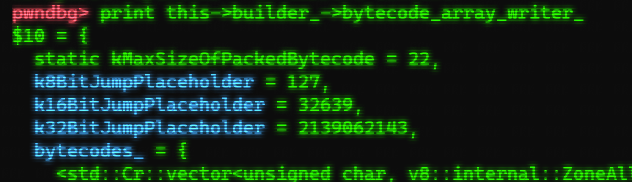
bytecodes是一个uint8_t型的向量:

Sparkplug(非优化编译器)
之前的分析器与字节码生成器都工作在MainThread中,而从sparkplug之后的编译器都工作在背景任务线程中,每个编译器都会创建一个新的线程,要使用哪个编译器受DefaultTimeFunction影响,DefaultTimeFunction是一个函数指针此函数用来获取当前时间并换算成秒:


当在WorkThread::Run函数执行任务时会调用DefaultWorkerThreadsTaskRunner::GetNext函数此函数会直接去调用DelayedTaskQueue::GetNext函数:

DelayedTaskQueue::GetNext函数会先调用MonotonicallyIncreasingTime来获取当前时间,实际上就是执行之前传入的函数指针DefaultTimeFunction,随后调用PopTaskFromDelayedQueue函数来获取要在WorkThread中执行的任务:


PopTaskFromDelayedQueue函数从delayed_task_queue_队列中获取任务,delayed_task_queue_中的first存储任务对应的时间,second存储任务对象,当遇到已经到截止时间的任务时就会将该任务从队列中取出并将该任务从队列中擦除:

截止时间等于添加任务时的时间加延时时间:
当触发sparkplug编译器时将会通过背景任务线程去执行BaselineCompiler::GenerateCode函数来进行基线编译,而sparkplug的核心就是一个for循环来遍历字节码,再用一个switch语句通过字节码来直接获取其对应的机器码:


整个sparkplug编译器实际上就只有一个for循环与switch语句。
Maglev(中间层优化编译器)
maglev编译器也是一个独立的背景任务线程,从MaglevCompiler::Compile函数开始执行,该函数会先通过zone创建一个图:

然后创建MaglevGraphBuilder对象,并执行build函数开始构建Maglev图

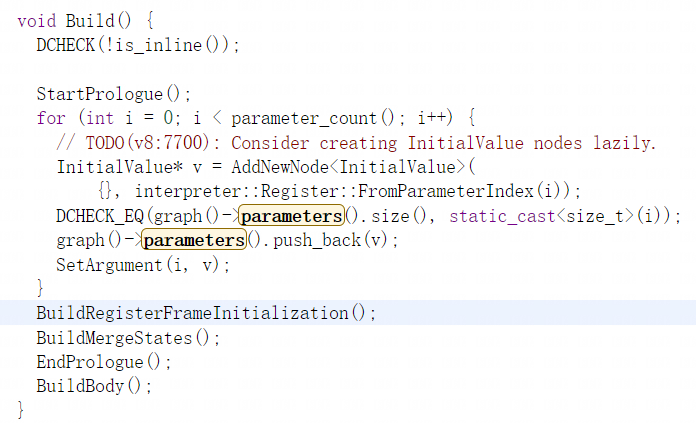
build函数会先根据参数个数创建对应的初始值,之BuildRegisterFrameInitialization函数用于为store/load寄存器的操作,维护一个InterpreterFrameState(IFS),它将每个寄存器(以及累加器)作为索引存储其对应的节点,BuildMergeStates函数用于合并循环分支,当多个跳转针对同一个字节码时,IFS会被合并并且为IFS中的每一个寄存器都创建一个phi节点,BuildBody函数用于遍历字节码根据字节码生成相应的SSA节点,StartPrologue函数用于创建新基础块,EndPrologue函数用于将创建的新基础块合并到FrameState中:
然后去创建图处理器,用于对寄存器分配与代码生成进行预处理:

ProcessGraph函数先用节点处理器对一些常量节点进行处理:
之后再对其他类型节点进行处理:
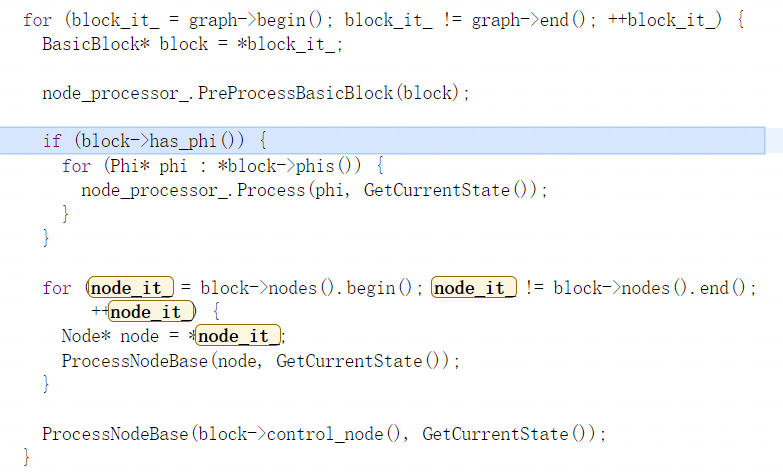
通过google的文档可知在之后的开发维护当中可能会为maglev编译器添加优化阶段,但目前还没有,所以在处理完图后就会去生成机器码:

Turbofan(优化编译器)
Turbofan与sparkplug一样会从背景任务线程开始执行,然后工作线程将会去调用优化编译任务函数:

最后会调用PipelineCompilationJob::ExecuteJobImpl函数,该函数再通过调用CreateGraph与OptimizeGraph函数开始执行Turbofan编译:
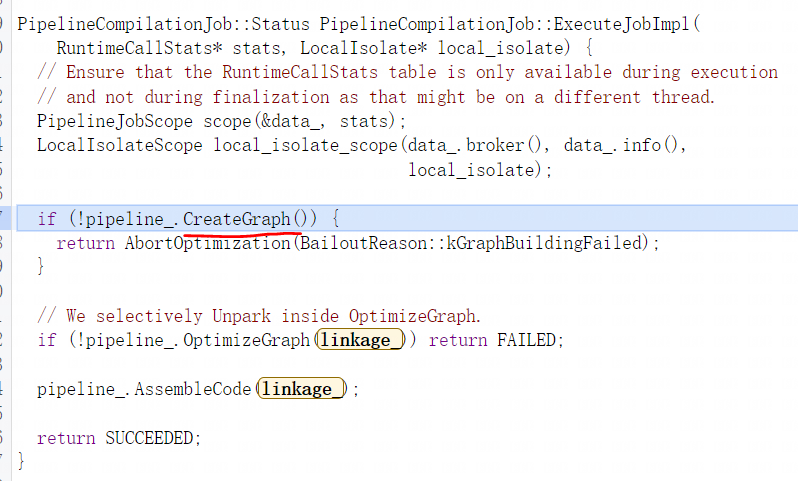
CreateGraph会去执行GraphBuilder与Inlining阶段,这两个阶段会创建后期优化所需要的图并对函数上下文进行内联:
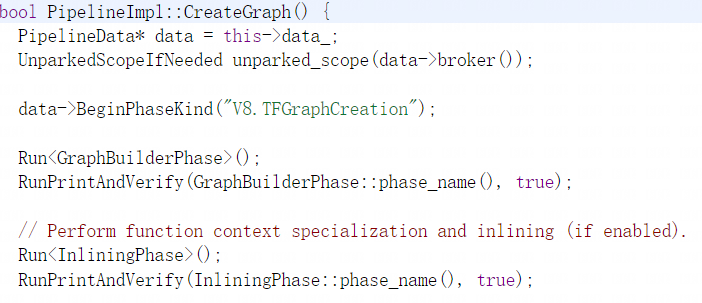
最后再为Typer优化添加相应的标记:

OptimizeGraph函数会去执行剩下的几个阶段,其中有一些阶段是能通过turbolizer看到的,还有一些是无法看到的例如TypeAssertions(类型断言)与DeadCodeElimination(死代码消除)阶段:

以上编译过程都是通过循环来触发的,如果使用v8内置的函数(例如%OptimizeFunctionOnNextCall等)来触发将不会通过背景任务线程,而是会通过Runtime函数来触发优化。